
HLS Learning P16 - Optimization-of-for-loop - Dataflow
1. Dataflow
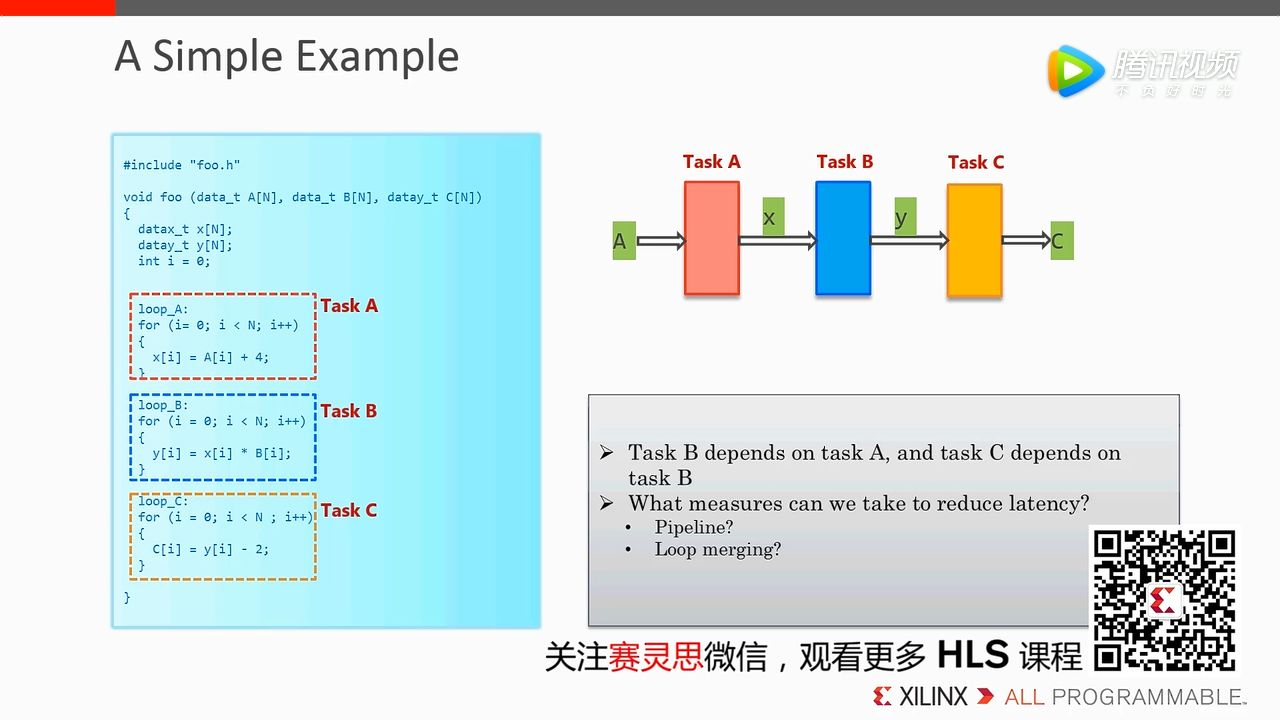
在这个例子中三个数组变量彼此依赖,这种情况下可以使用 Pipeline 进行优化,而 Loop merging 是不可以的,因为他们彼此之间有依赖关系。
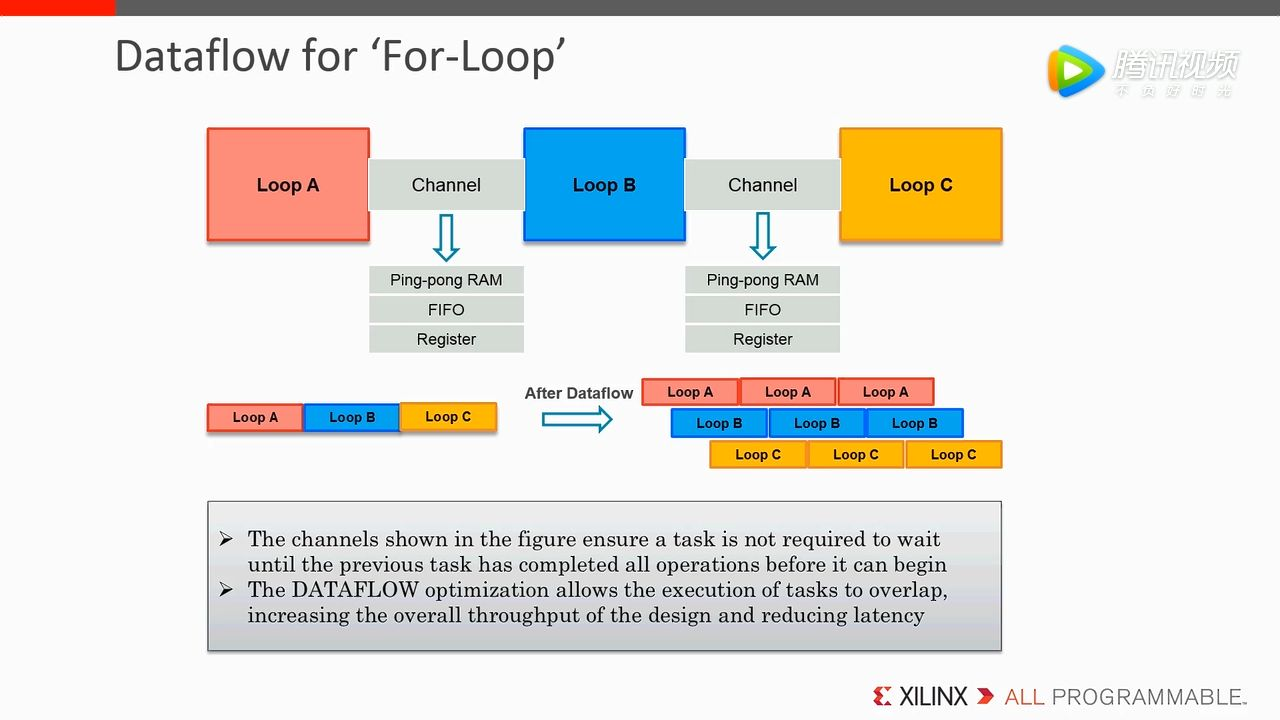
引出 Dataflow 这种优化方式,两两模块之间插入了 Channel,这种方式可以确保当前 Task 执行不需要等待上一个 Task 执行结束,并且允许 task 执行存在 overlap,这种 overlap 可以帮助我们降低 latency,从而提高吞吐率。在这个例子中,Loop B 不需要等待 Loop A 循环完全结束,只有它有输出就可以使用当前的输出去执行 Loop B。
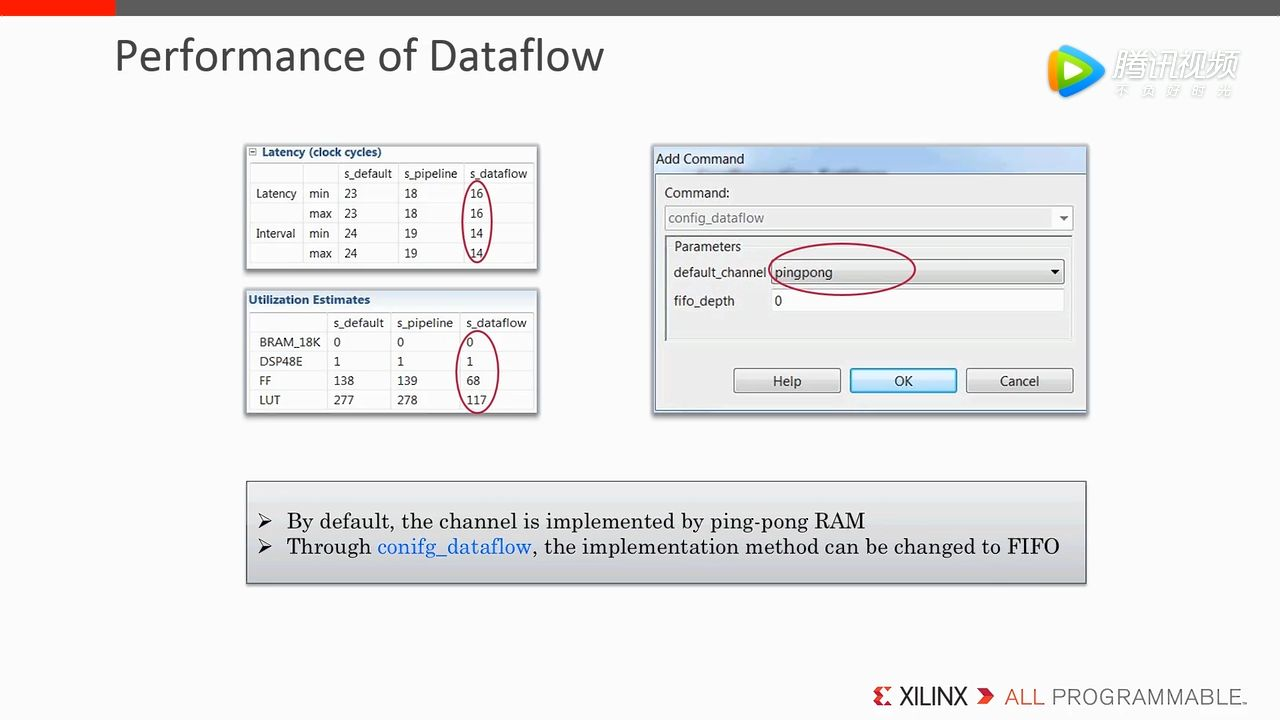
可以通过 Configure dataflow 来配置 channel 的类型,默认情况下使用 ping-pong RAM。
Dataflow 的本质,举个例子就像是货物从 A 搬运到 B,可以等货物到一定数量后使用货车一口气拉过去,也可以在两者之间建立传送带来多少传多少。即在使用之前只有 for-loop 结束才能获取到整块数据,而使用 channel 可以将数据的传递建立通道,获取到一部分就直接传递到下一个部分。
并不是所有的 for-loop 都可以使用 dataflow,如下几种情况使用时需要做修改和改善。下面讲前两个

2. Examples
a. Single-producer-consumer model
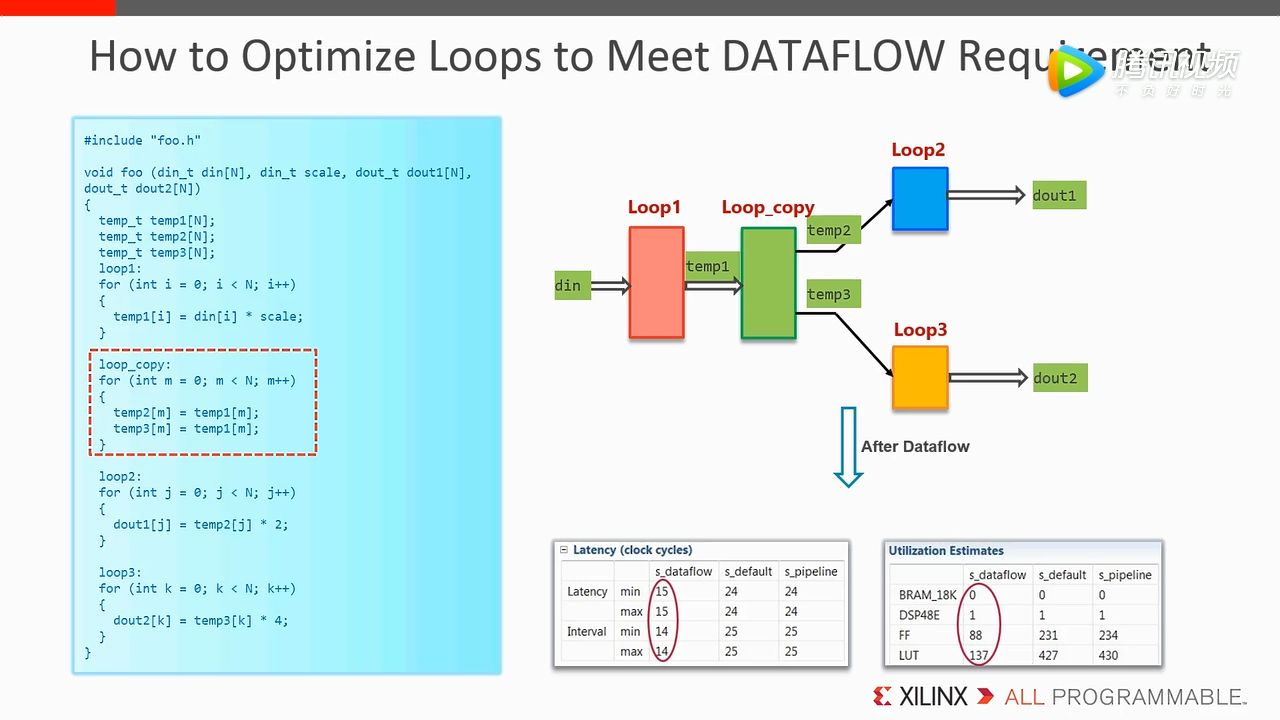
如下图的例子其实是不能使用 Dataflow 的,因为 Loop 2 和 Loop 3 依赖同一个变量 temp1,在 Loop2 使用这个变量时 Loop3 无法使用。
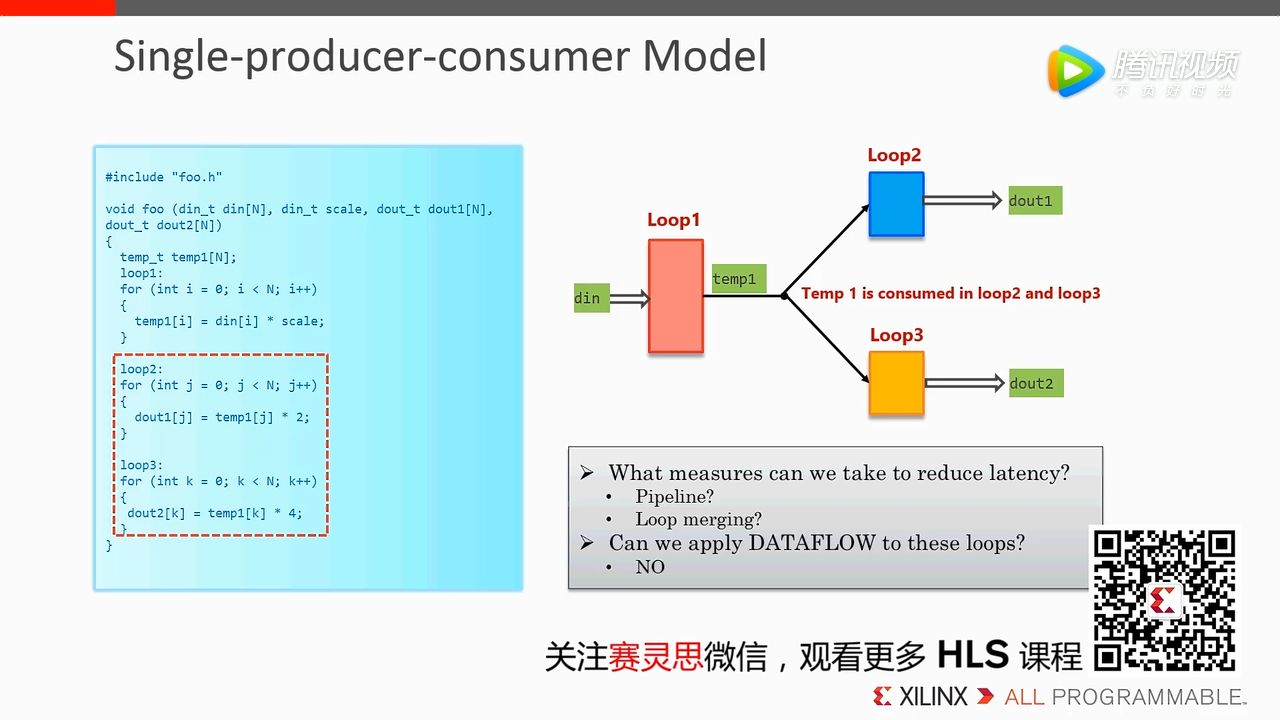
通过 loop-copy 生成不同的两个变量,来避免 temp1 竞争,这样便可以使用 Dataflow。
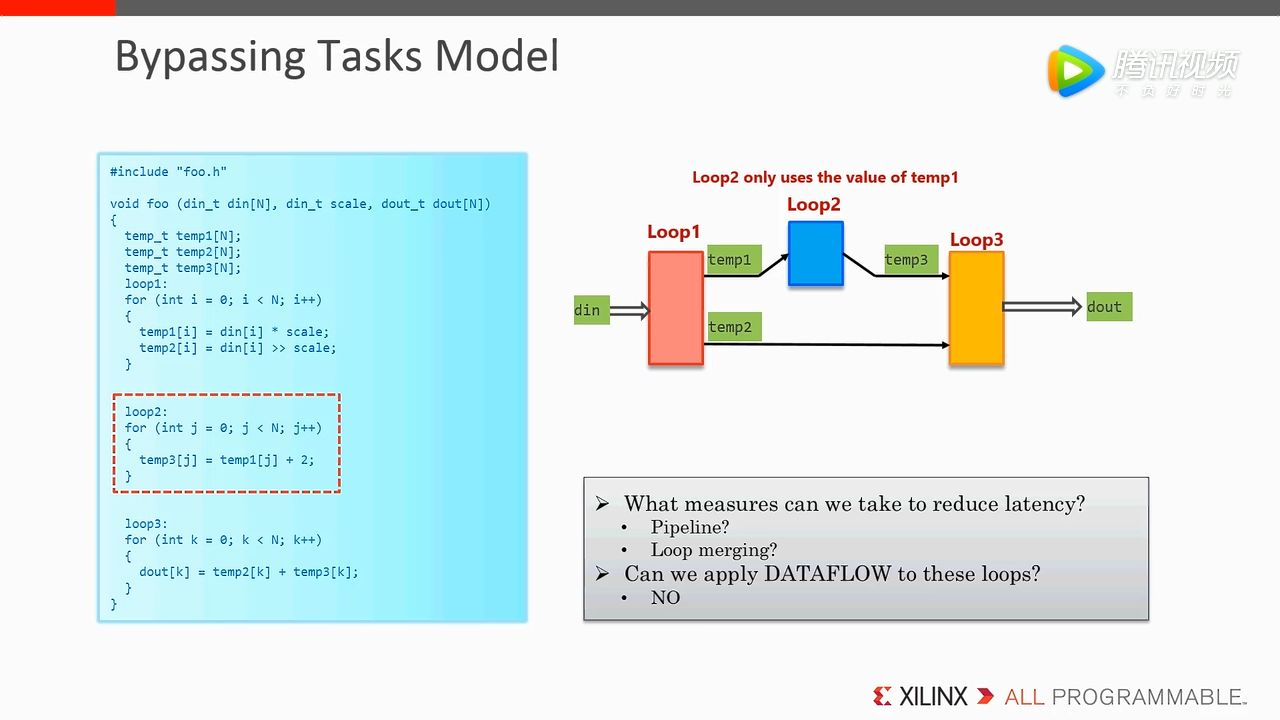
2. Bypassing Tasks Model
这个稍微有点麻烦,如果单纯为了记住的话,可以理解为需要使用 Dataflow 的多个 for-loop 不能存在跨模块的依赖关系,只能依次传递过去。比如这里画成流程图后可以看到 Loop3 是依赖 Loop2 生成的 temp3 的,但同时依赖的 temp2 却是在 Loop2 之前的 Loop1 中生成的。结合前面介绍使用的原理图推测,for-loop 之前插入 channel 只能是两两之间,不能跨模块,比如这里如果在 Loop1 和 Loop2 之间插入为了 temp1,在 Loop2 和 Loop3 之间插入为了 temp3,那么就无法再插入一个 channel 为了 temp2 数据了。
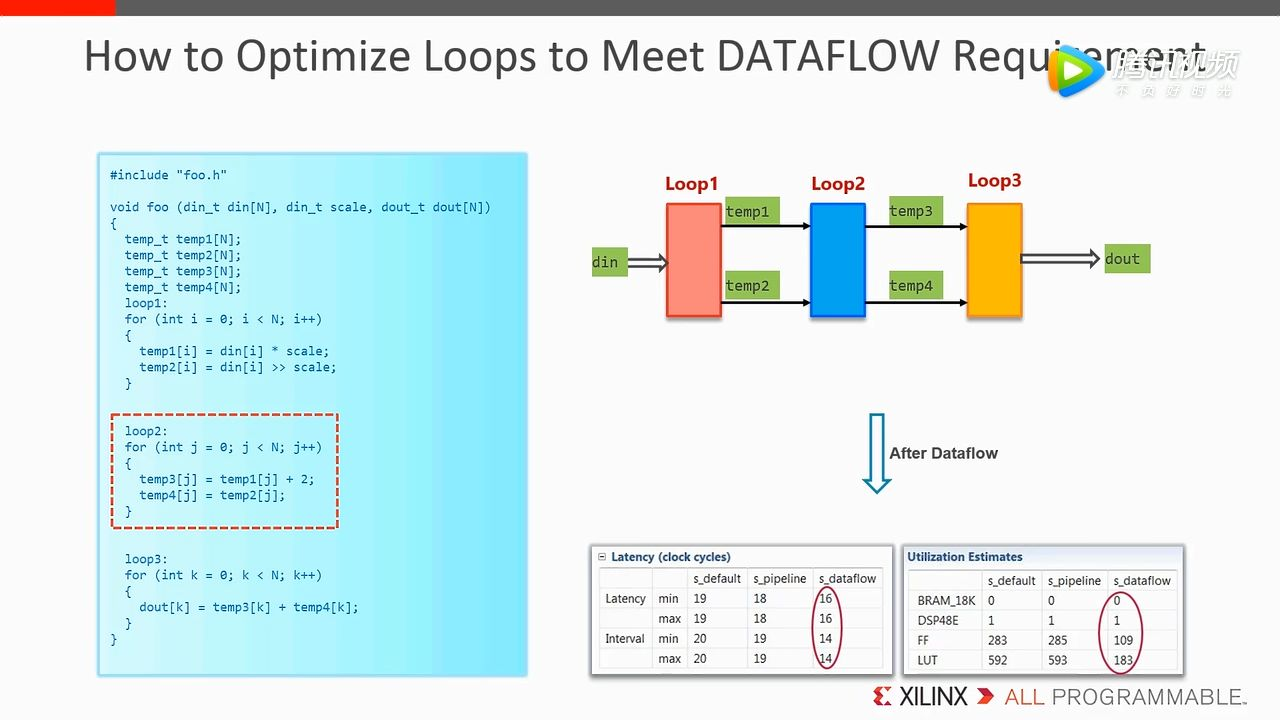
根据前面的分析,这里的修改也是保证了数据的传递是 module by module 的。
3. Configuration
Vivado HLS 会将 channel 配置成哪种类型,取决于其中的数据类型。如果是 scalar,pointer 或者 reference,一般会被配置成 FIFO;如果是数组,则根据数据顺序与否配置成 FIFO 或者 ping-pong。

手动进行配置,注意配置 FIFO 时候 fifo_depth 要注意,否则在 C/RTL 协同仿真时候会报错。

4. Summary
