
HLS Learning P14 - Optimization of for-loop - Performance Metrics
从这一节起开始一个新的 Chapter -> Optimization of for-loop,大约有 5 节课程的内容,从不同方面介绍如何对 C 语言下最常见的 for-loop 从底层角度进行优化。
这节课所要讲解的内容如下,包括与 for-loop 相关的基本概念,对 for-loop 进行 pipelining 和 unrolling,以及迭代变量类型的影响。

1. Basic concepts associated with for-loop
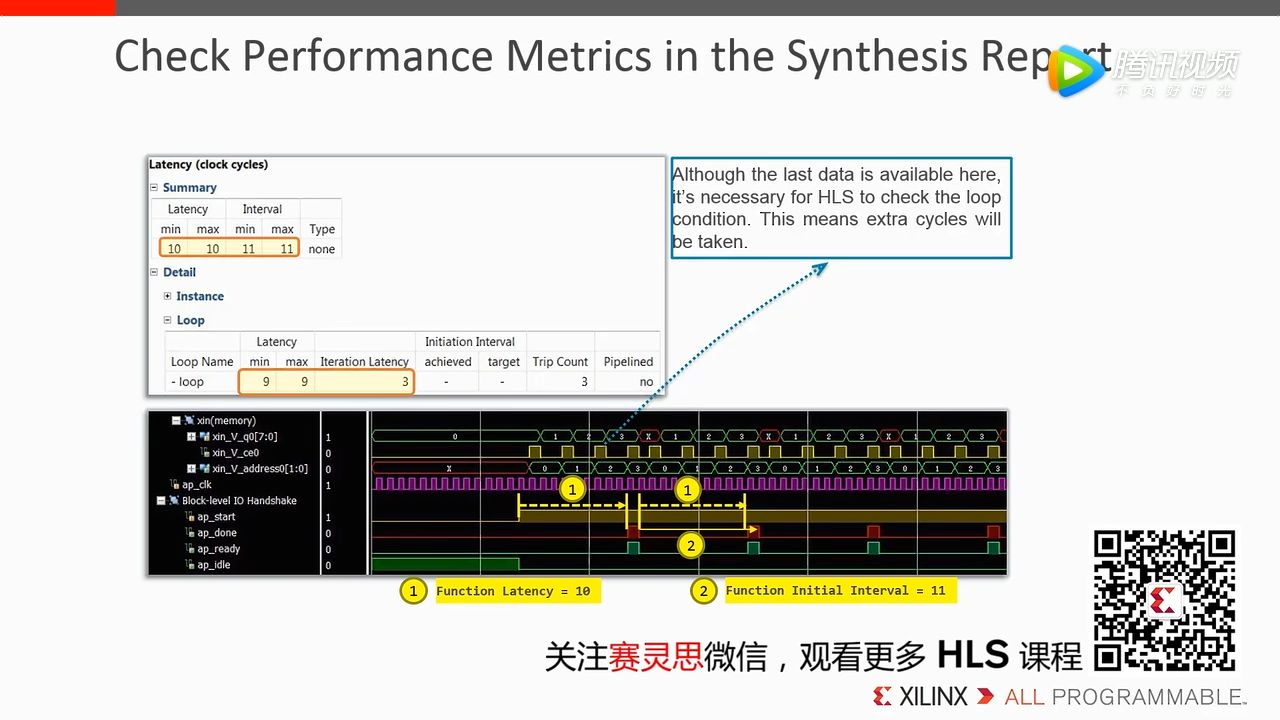
下图中的一段代码按照 clock cycle 进行拆分,for-loop 对应 1,2,3 步。其中的 Loop Interation Latency 以及 Loop II 都是 for-loop 中很重要的指标,从 report 中后续可以查看到。

下图便是代码编译后得到的 report 信息,可以看到 Loop 一栏中有上面图中提到的几个参数。从波形图来看,当 ap_start 为高时开始,ap_done 为高时结束,便可以得到每次 loop 的 latency 以及 interval。有一点需要注意的是,硬件电路在执行 for 循环时并不能在每次 loop 结束后马上进入下一个 loop,而是需要判断循环变量是否超出了边界,这便是多出来的一个时钟周期的原因。
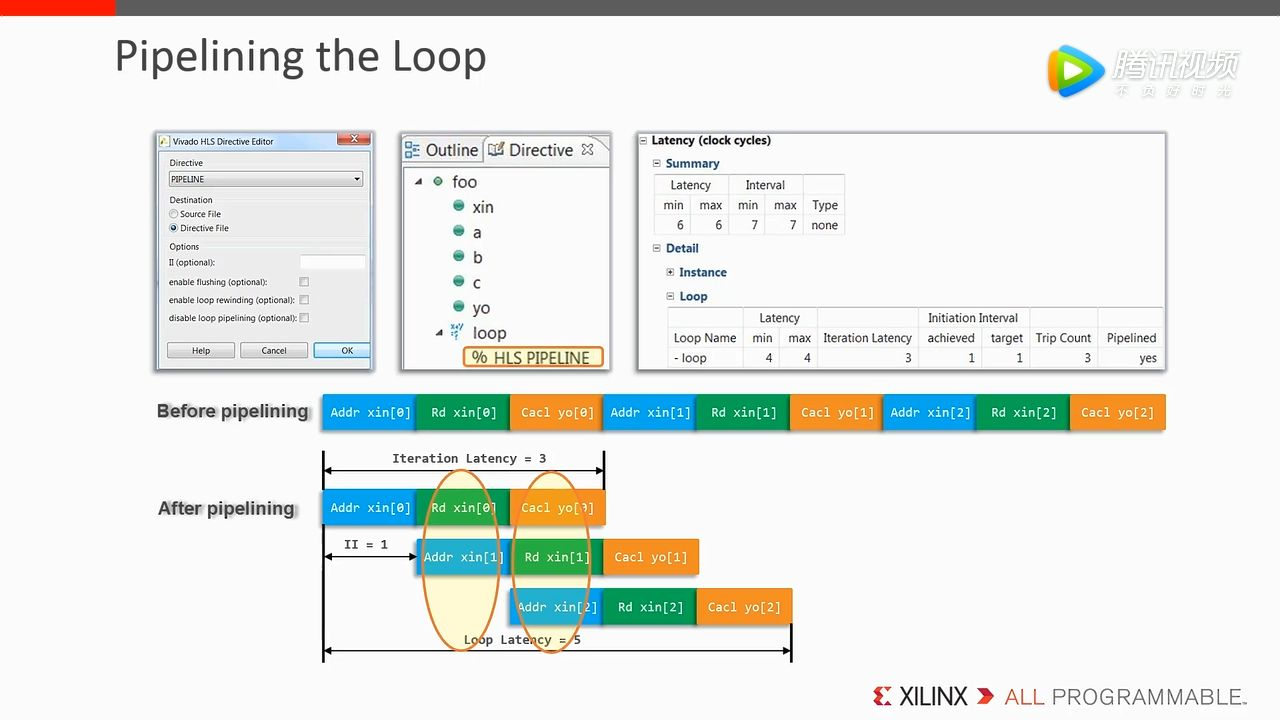
2. Pipelining the Loop
这种方法算是对 for-loop 最常规的一种优化了,设置方法也很简单,如下图所示。思路也很简单,将原先的串行改为并行,把不同指令操作的执行给并行化。
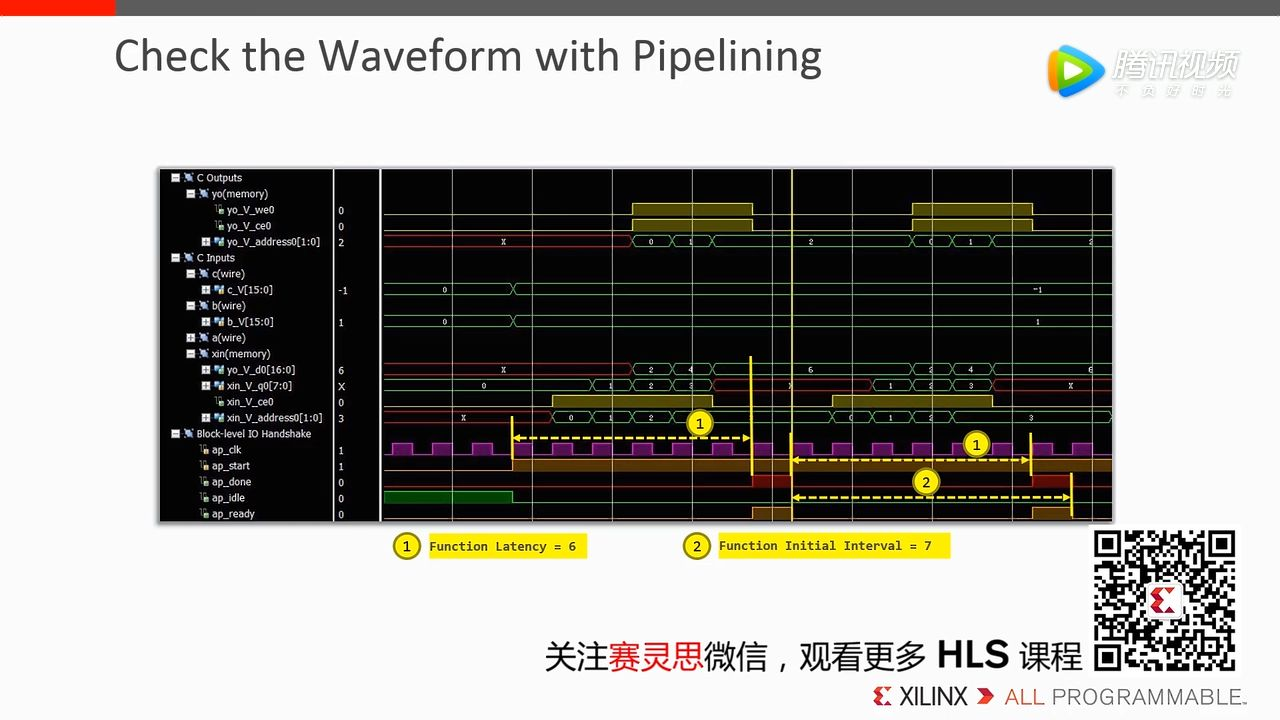
从波形图中可以看到 latency 和 interval 都大大减少了。
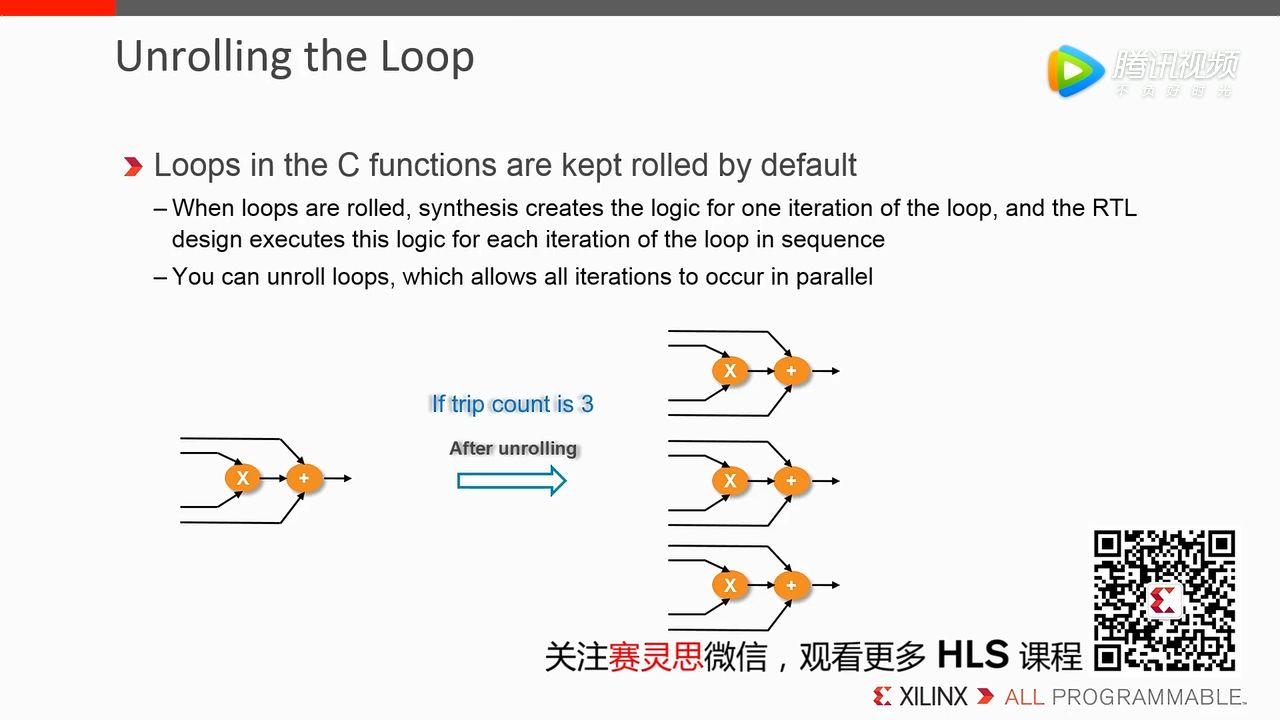
3. Unrolling the Loop
既然提到了 Unrolling(展开),那么就要说到默认情况下 for-loop 其实是被折叠的。意思是,每次 for-loop 都是使用同一套电路,只是他们被分时复用了。展开就意味着这个 for-loop 被复制了多份,占用资源变多,相当于以面积换时间。
也可以进行部分展开,用 C 语言表示的话可以拆分成如下代码

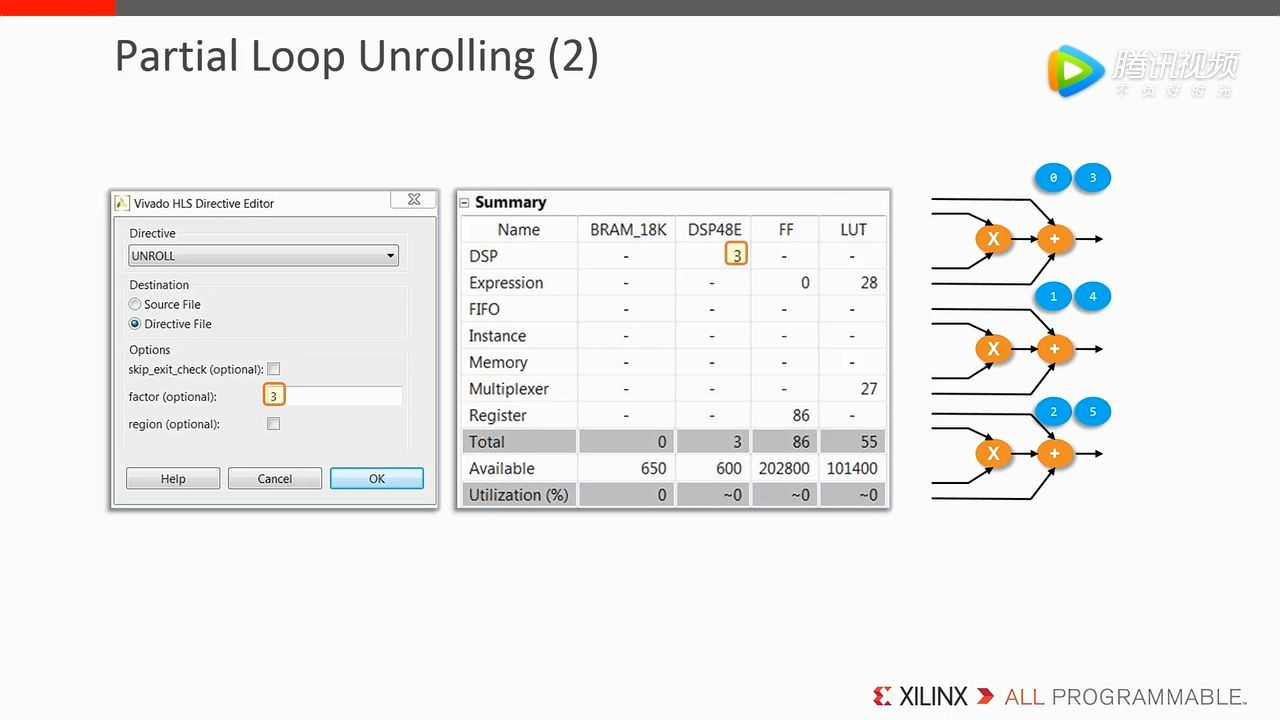
在 Directive 中需要修改 factor,其参数代表将 for-loop 复制了几份。从硬件层面来看如下图右侧所示
变量 i 声明为 int 或者 ap_int<4> 没有影响,vivado HLS 主要考虑的是变量的范围,这个范围决定了资源的使用量。

4. Summary
