Notes
Bugs
Degraded data redundancy
集群状态如下
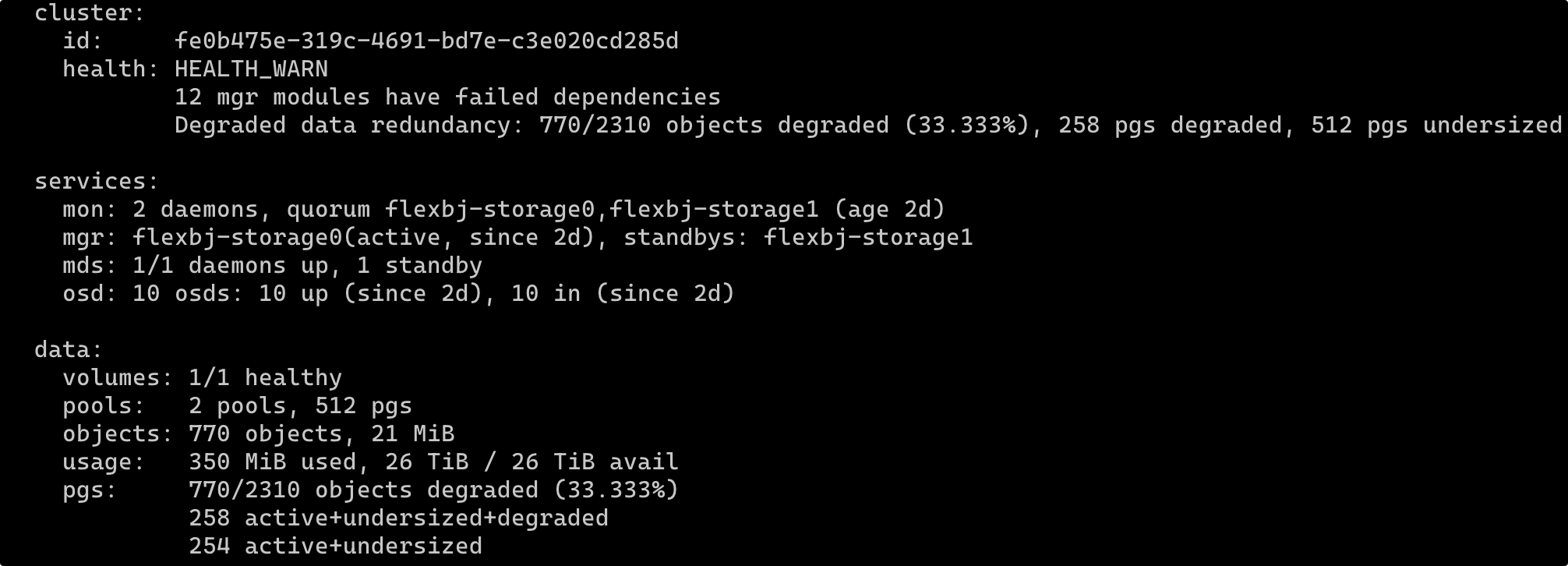
建立 CephFS 并挂载之后往其中简单写入了一些文件,没多大但却一直处于 degraded 状态。
运行 ceph health detail 打印信息如下
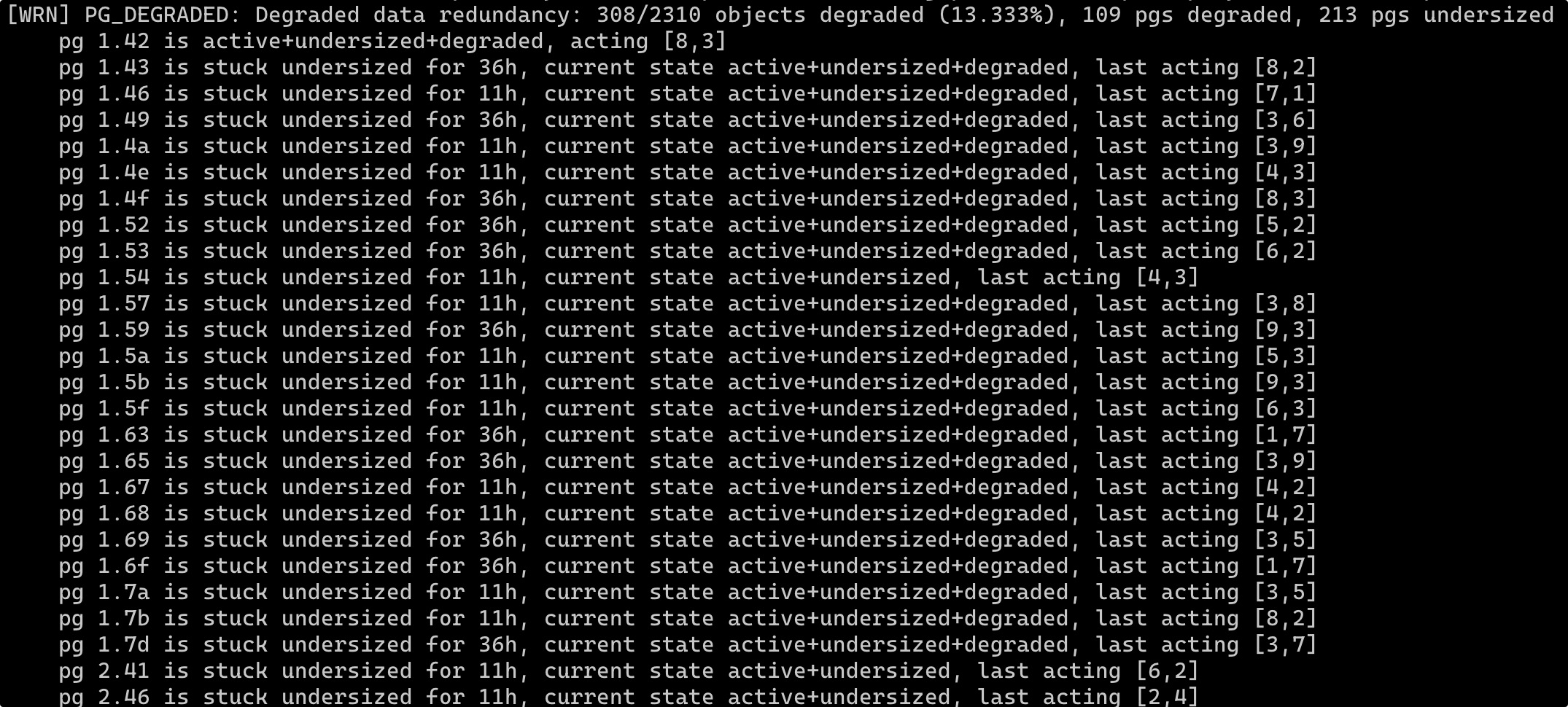
根据参考链接 2 中图的描述来看,问题应该是出在 PG 当前 Acting Set 小于存储池副本数,从 last acting [3,7] 这样的信息也可以看出

运行 ceph pool ls detail 命令查看确实设置的副本数为 3,不理解为什么会缺少一个副本备份

最后解决方法很粗暴,将三副本的设置改为了二副本。一方面两台机器就存放在一台机房一台机架, 一损俱损;二是考虑到硬盘本身故障率比较低,就 10 个 OSD 的量不会出现同时多个故障问题(相比硬件软件出问题概率更大)。因此趁此机会设置为双副本,增加响应速度也能腾出更多的空间。
参考链接 3,使用命令及后来状态如下
1
2
3
4
5
6
7
| root@storage0:/home/admin# ceph osd pool set cephfs_data size 2
set pool 1 size to 2
root@storage0:/home/admin# ceph osd pool set cephfs_metadata size 2
set pool 2 size to 2
root@storage0:/home/admin# ceph osd pool ls detail
pool 1 'cephfs_data' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 256 pgp_num 256 autoscale_mode on last_change 109 flags hashpspool stripe_width 0 application cephfs read_balance_score 1.37
pool 2 'cephfs_metadata' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 256 pgp_num 256 autoscale_mode on last_change 111 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 16 recovery_priority 5 application cephfs read_balance_score 1.37
|
之后集群也恢复了正常。
Reference
- kubernetes - Ceph: fix active+undersized+degraded pgs after removing an osd? - Stack Overflow
- 分布式存储Ceph之PG状态详解 - 知乎 (zhihu.com)
- ceph设置副本的数目-2019014补_51CTO博客_ceph 副本数
